Raspberry Pi4 画像認識 ~⑧独自画像学習 RPi上で推論~
①~⑦までで行った、セットアップから学習まで行ってきました。
学習モデルが完成したので、そのモデルをエッジデバイスとするラズパイに移行してリアルタイム推論を行ってシリーズは終了です。
1. google driveからラズパイへ.tfliteモデルを移行する
windows <-> ラズパイ間のファイルのやり取りを行うために、「samba」というファイルサーバーを入れます。
ここは、ラズパイのターミナル上で行います。
1-1. sambaをインストール
sudo apt install samba -y
1-2. 設定ファイルをconfファイルに追記
バックアップを取っておきます。
sudo cp /etc/samba/smb.conf /etc/samba/smb.conf_backup
nanoというエディタで編集します。
sudo nano /etc/samba/smb.conf
[pi] comment = pi path = /home/pi force user = pi read only = no browsable = yes public = yes
sambaサービスの再起動
sudo systemctl restart smbd
windowsエクスプローラーの「ネットワーク」を開いて
¥¥(ラズパイのIPアドレス)を入力すると接続できます。
そしたら、以前作成した.tfliteファイルをラズパイ上の適当なフォルダに移行してあげます。
2. 推論プログラム作成
基本的に以前作成したプログラムを使用しますが、一部映像をリアルタイムで推論できるように変更します。
2-1. ライブラリのインポート
まず、必要なライブラリをインポートします。
from picamera2.picamera2 import * import time import cv2 import numpy as np import matplotlib.pyplot as plt import tensorflow as tf from tflite_support import metadata
2-2. 準備
MODEL_PATH = "model.tfliteの絶対パス" SAVE_PATH = "撮影した画像の保存ディレクトリの絶対パス" # パイカメラの準備(bullseye用) camera = Picamera2() camera.start_preview() camera.configure(camera.preview_configuration()) camera.start() # tfliteのメタデータ(グー/チョキ/パー)の取得 displayer = metadata.MetadataDisplayer.with_model_file(MODEL_PATH) for i, file_name in enumerate(displayer.get_packed_associated_file_list()): displayer.get_associated_file_buffer(file_name) label = str(displayer.get_associated_file_buffer(file_name))[2:] label_list = label.split('\\n') classes = label_list[:-1]
2-3. 映像をテンソルに変換する関数
コメントのように、映像をnumpy配列として読み込むためそれをそのままtensor型へ変更します。
def preprocess_image(image_path, input_size): """Preprocess the input image to feed to the TFLite model""" """ # 画像を1枚ずつ読み込む場合 img = tf.io.read_file(image_path) img = tf.io.decode_image(img, channels=3) img = tf.image.convert_image_dtype(img, tf.uint8) """ # 映像をnumpy配列として読み込むので、そのままtensorへ変更する img = tf.convert_to_tensor(image_path) # 変更なし original_image = img resized_img = tf.image.resize(img, input_size) resized_img = resized_img[tf.newaxis, :] resized_img = tf.cast(resized_img, dtype=tf.uint8) return resized_img, original_image
2-4. オブジェクト(手)を探す関数
変更ありません
def detect_objects(interpreter, image, threshold): """Returns a list of detection results, each a dictionary of object info.""" signature_fn = interpreter.get_signature_runner() # Feed the input image to the model output = signature_fn(images=image) # Get all outputs from the model count = int(np.squeeze(output['output_0'])) scores = np.squeeze(output['output_1']) classes = np.squeeze(output['output_2']) boxes = np.squeeze(output['output_3']) results = [] for i in range(count): if scores[i] >= threshold: result = { 'bounding_box': boxes[i], 'class_id': classes[i], 'score': scores[i] } results.append(result) return results
2-5.推論実行関数
def run_odt_and_draw_results(image_path, interpreter, threshold=0.6): """Run object detection on the input image and draw the detection results""" # Load the input shape required by the model _, input_height, input_width, _ = interpreter.get_input_details()[0]['shape'] # Load the input image and preprocess it preprocessed_image, original_image = preprocess_image( image_path, (input_height, input_width) ) # Run object detection on the input image results = detect_objects(interpreter, preprocessed_image, threshold=threshold) # Plot the detection results on the input image original_image_np = original_image.numpy().astype(np.uint8) for obj in results: # Convert the object bounding box from relative coordinates to absolute # coordinates based on the original image resolution ymin, xmin, ymax, xmax = obj['bounding_box'] xmin = int(xmin * original_image_np.shape[1]) xmax = int(xmax * original_image_np.shape[1]) ymin = int(ymin * original_image_np.shape[0]) ymax = int(ymax * original_image_np.shape[0]) # Find the class index of the current object class_id = int(obj['class_id']) # Draw the bounding box and label on the image color = [int(c) for c in COLORS[class_id]] cv2.rectangle(original_image_np, (xmin, ymin), (xmax, ymax), color, 2) # Make adjustments to make the label visible for all objects y = ymin - 15 if ymin - 15 > 15 else ymin + 15 label = "{}: {:.0f}%".format(classes[class_id], obj['score'] * 100) cv2.putText(original_image_np, label, (xmin, y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2) # Return the final image original_uint8 = original_image_np.astype(np.uint8) return original_uint8
2-6. ラズパイカメラからの映像をrgbへ変更する関数
この部分は要改良の余地ありです。
ラズパイからの映像をpicamera2モジュールで読み込むと、rgbaという形式になっていました。
numpy配列をtensorとして読み込むためには、rgba -> rgbへ次元を変更する必要があります。
そのため、以下の関数を追加しました。
def rgba2rgb( rgba, background=(255,255,255) ): # reference(https://stackoverflow.com/questions/50331463/convert-rgba-to-rgb-in-python) row, col, ch = rgba.shape if ch == 3: return rgba assert ch == 4, 'RGBA image has 4 channels.' rgb = np.zeros( (row, col, 3), dtype='float32' ) r, g, b, a = rgba[:,:,0], rgba[:,:,1], rgba[:,:,2], rgba[:,:,3] a = np.asarray( a, dtype='float32' ) / 255.0 R, G, B = background rgb[:,:,0] = r * a + (1.0 - a) * R rgb[:,:,1] = g * a + (1.0 - a) * G rgb[:,:,2] = b * a + (1.0 - a) * B return np.asarray( rgb, dtype='uint8' )
2-7.メイン実行プログラム
上記で作成した関数を使用して実行関数を作成して終了です。
if __name__ == '__main__': # 画像を撮影した際の番号 count = 1 # 推論の際の四角の色を指定 COLORS = np.random.randint(0, 255, size=(len(classes), 3), dtype=np.uint8) # 推論と映像表示 while True: image = camera.capture_array() image = rgba2rgb(image) # rgba を rgb へ変更 # 映像表示を終了する際のキー指定 key = cv2.waitKey(1) if key == 27: # when ESC key is pressed break break # 推論 interpreter = tf.lite.Interpreter(model_path=str(MODEL_PATH)) interpreter.allocate_tensors() result = run_odt_and_draw_results(image, interpreter=interpreter) # 撮影をする際のキー指定 if key == ord('c'): # when "c" key is pressed capture image as "SAVE_PATH/(count).png" cv2.imwrite(SAVE_PATH + str(count) + '.png', result) count += 1 cv2.imshow('View', result) # 終了する際のプログラム camera.close() cv2.destroyAllWindows()
3. 推論実行
上記で準備したプログラムをラズパイ上で実行すると、このようになりました。
パー

チョキ

グー

まず、全体的に画像が青みがかっています。
これは、「rgba2rgb」関数の部分で生じている問題です。今後調査をして改良しようと思います。
次に、推論精度が全体的に低めです。
これは、モデル作成段階である程度分かっていたことで、画像の枚数を増加させることで改善できると思います。
おおざっぱではありますが、0(ラズパイのセットアップ)~10(オリジナルモデルの作成・推論)までを解説してまいりました。
これで簡単なPoC程度を行うことはできるかと思います。
さらなる改善のためには、機械学習自体を深く学んだり、問題そのものへの深い理解が必要になると思います。
実際に準備から推論することを経験する人はなかなかいないと思います。
また、セットアップ->オリジナルモデルの作成->推論までを一挙に解説している記事などがなかったため作成してみました。
情報は"生もの"で時間経過と共に、各ライブラリのアップデートやサポート終了等によって使えなくなってしまいます。
可能な限り最新の情報を得ながら実践してみてください。
お疲れさまでした。
-
-
-
-
- 関連記事-----
-
-
-
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
Raspberry Pi4 画像認識 ~⑦独自画像学習 推論~
独自の画像を使って学習モデルを作るところまで完了しました。
実際にcolab上で学習に使用していない新しい画像を用いて、推論を行ってみましょう。
1. 下準備
!pip install tflite-support
from pathlib import Path import cv2 from PIL import Image import numpy as np import matplotlib.pyplot as plt import tensorflow as tf from tflite_support import metadata
MODEL_PATH = Path("※model.tfliteのパス") IMAGE_PATH = Path("※新たな画像のパス") IMAGE_LIST = list(IMAGE_PATH.glob('*'))
今回は、学習で使用していない「新たな画像」をどこかから入手してgoogle driveに保存します。
手っ取り早いのはスマホで撮影した画像でよいかと思います。
ただし、iPhoneで撮影した画像は「.HEIC」という形式のため、「.jpg/.png」に変換する必要がありますので注意してください。
2. tfliteモデル内の情報を抜き出す
公式のプログラムをそのまま上から実行していけば、推論までたどり着きますが、
ラズパイへ移行した後に、tfliteのメタデータを取得する方法が記載されていなかったため、
ここでは、別プログラムとして推論を行います。
displayer = metadata.MetadataDisplayer.with_model_file(MODEL_PATH) print("Associated file(s) populated:") for file_name in displayer.get_packed_associated_file_list(): print("file name: ", file_name) print("file content:") print(displayer.get_associated_file_buffer(file_name))
Associated file(s) populated: file name: labelmap.txt file content: b'label\nScissors\nrock\npaper\n'
学習したtfliteモデルで推論した結果から、ラベルデータや、推論値、bbox値等を取得しなければなりません。
ラベルデータ以外は公式プログラムをそのまま参照できるので、ラベルデータを探します。
label = str(displayer.get_associated_file_buffer(file_name)) label = label[2:] label_list = label.split('\\n') classes = label_list[:-1] print(len(classes)) print(classes)
ラベル出力のリスト中に、'label'を含ませる必要があります。
3. 推論用関数の定義
def preprocess_image(image_path, input_size): """Preprocess the input image to feed to the TFLite model""" img = tf.io.read_file(image_path) img = tf.io.decode_image(img, channels=3) img = tf.image.convert_image_dtype(img, tf.uint8) original_image = img resized_img = tf.image.resize(img, input_size) resized_img = resized_img[tf.newaxis, :] resized_img = tf.cast(resized_img, dtype=tf.uint8) return resized_img, original_image
「.jpg/.png」形式のデータを、学習モデル.tfliteが読めるように変換する関数です。
def detect_objects(interpreter, image, threshold): """Returns a list of detection results, each a dictionary of object info.""" signature_fn = interpreter.get_signature_runner() # Feed the input image to the model output = signature_fn(images=image) # Get all outputs from the model count = int(np.squeeze(output['output_0'])) scores = np.squeeze(output['output_1']) classes = np.squeeze(output['output_2']) boxes = np.squeeze(output['output_3']) results = [] for i in range(count): if scores[i] >= threshold: result = { 'bounding_box': boxes[i], 'class_id': classes[i], 'score': scores[i] } results.append(result) return results
画像の中の物体を推論するための関数です。
ここで、推論値やbboxの値がわかります。
結果は、辞書として出力されてきます。
def run_odt_and_draw_results(image_path, interpreter, threshold=0.5): """Run object detection on the input image and draw the detection results""" # Load the input shape required by the model _, input_height, input_width, _ = interpreter.get_input_details()[0]['shape'] # Load the input image and preprocess it preprocessed_image, original_image = preprocess_image( image_path, (input_height, input_width) ) # Run object detection on the input image results = detect_objects(interpreter, preprocessed_image, threshold=threshold) # Plot the detection results on the input image original_image_np = original_image.numpy().astype(np.uint8) for obj in results: # Convert the object bounding box from relative coordinates to absolute # coordinates based on the original image resolution ymin, xmin, ymax, xmax = obj['bounding_box'] xmin = int(xmin * original_image_np.shape[1]) xmax = int(xmax * original_image_np.shape[1]) ymin = int(ymin * original_image_np.shape[0]) ymax = int(ymax * original_image_np.shape[0]) # Find the class index of the current object class_id = int(obj['class_id']) # Draw the bounding box and label on the image color = [int(c) for c in COLORS[class_id]] cv2.rectangle(original_image_np, (xmin, ymin), (xmax, ymax), color, 2) # Make adjustments to make the label visible for all objects y = ymin - 15 if ymin - 15 > 15 else ymin + 15 label = "{}: {:.0f}%".format(classes[class_id], obj['score'] * 100) cv2.putText(original_image_np, label, (xmin, y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2) # Return the final image original_uint8 = original_image_np.astype(np.uint8) return original_uint8
上記2つの関数を使って、物体検出を行う関数です。
4. 推論
image_path = str(IMAGE_LIST[0]) interpreter = tf.lite.Interpreter(model_path=str(MODEL_PATH)) interpreter.allocate_tensors() COLORS = np.random.randint(0, 255, size=(len(classes), 3), dtype=np.uint8) detection_result_image = run_odt_and_draw_results(image_path=image_path, interpreter=interpreter) # Show the detection result Image.fromarray(detection_result_image)
実際に推論をしてみた画像がこちら

チョキ単体の場合、「チョキ:86%」という結果に。
一方、すべての手が1枚に移っている画像では、
グーは検出されず、パーは「チョキ:66%」と誤認識され、チョキは「チョキ:54%」となっています。
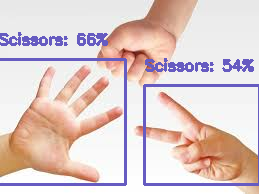
後者のように誤認識されてしまう理由として、
「学習画像内に手が一つしかなかったこと」「画像いっぱいに手が写っていたこと」などが考えられると思います。
2枚目の写真のように、複数手がある画像を学習しておらず、かつ手が小さいため推論制度が低下した可能性があります。
次回は、このモデルをラズパイへ移してカメラから推論します。
-
-
-
-
- 関連記事-----
-
-
-
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
Raspberry Pi4 画像認識 ~⑥独自画像学習 独自画像の学習~
アノテーションCSVを変更し、Tensorflow model makerの物体検出で使用できる形に変更しました。
今回は、この変更したCSVを用いてモデルを学習させます。
1.下準備
基本的に、Tensorflowの公式ドキュメント
Object Detection with TensorFlow Lite Model Maker
に沿って行います。
!pip install -q --use-deprecated=legacy-resolver tflite-model-maker !pip install -q pycocotools !pip install -q opencv-python-headless==4.1.2.30
google colabにtflite model maker / pycocotools / opencvをインストール
import numpy as np from pathlib import Path from tflite_model_maker.config import QuantizationConfig from tflite_model_maker.config import ExportFormat from tflite_model_maker import model_spec from tflite_model_maker import object_detector import tensorflow as tf assert tf.__version__.startswith('2') tf.get_logger().setLevel('ERROR') from absl import logging logging.set_verbosity(logging.ERROR)
ライブラリインポート
ANNO_CSV = Path("※アノテーションdataset.csvのパス") SAVE_PATH = Path("※今回制作するmodelの保存パス")
パスの指定
spec = model_spec.get('efficientdet_lite0')
ここで、物体検出モデルを指定します。ここでは、EfficientNetというニューラルネットワークモデルをtfliteで利用できるように変換したものを指定しています。
公式ではefficientdet_lite0~4をサポートしているようで、数字が大きくなるほど精度が高くなり、推論速度が遅くなるようです。
train_data, validation_data, test_data = object_detector.DataLoader.from_csv(ANNO_CSV)
前回修正したCSVファイルを使って、訓練データ、評価データ、テストデータを作成
model = object_detector.create(train_data, model_spec=spec, batch_size=8, train_whole_model=True, validation_data=validation_data)
ここで、学習モデルを作成します。
画像枚数によりますが、じゃんけん画像の場合20~30分程度時間がかかります。
メモリ不足になる場合は、「batch_size=」の部分の数字を小さくするとうまくいこことが多いです。
batch_size=8は、8枚の画像を1セットとして学習させることをさしています。
batch_sizeを大きくすれば、まとめてたくさんの画像を学習でき、batch_sizeを小さくすれば、少量ずつ画像を学習させることができます。
画像が多い場合、batch_sizeを大きくすることで学習時間を短縮することもできます。
適宜変更して対応してみてください。
Epoch 1/50 16/16 [==============================] - 73s 3s/step - det_loss: 1.6946 - cls_loss: 1.1217 - box_loss: 0.0115 - reg_l2_loss: 0.0633 - loss: 1.7579 - learning_rate: 0.0090 - gradient_norm: 1.3597 - val_det_loss: 1.5367 - val_cls_loss: 1.0551 - val_box_loss: 0.0096 - val_reg_l2_loss: 0.0633 - val_loss: 1.6001 Epoch 2/50 16/16 [==============================] - 40s 2s/step - det_loss: 1.3411 - cls_loss: 0.9364 - box_loss: 0.0081 - reg_l2_loss: 0.0633 - loss: 1.4044 - learning_rate: 0.0100 - gradient_norm: 1.7222 - val_det_loss: 1.1773 - val_cls_loss: 0.8345 - val_box_loss: 0.0069 - val_reg_l2_loss: 0.0633 - val_loss: 1.2406 Epoch 3/50 16/16 [==============================] - 39s 2s/step - det_loss: 0.9503 - cls_loss: 0.6632 - box_loss: 0.0057 - reg_l2_loss: 0.0634 - loss: 1.0137 - learning_rate: 0.0099 - gradient_norm: 1.8717 - val_det_loss: 0.9387 - val_cls_loss: 0.5932 - val_box_loss: 0.0069 - val_reg_l2_loss: 0.0634 - val_loss: 1.0021 Epoch 4/50 16/16 [==============================] - 40s 2s/step - det_loss: 0.7808 - cls_loss: 0.5625 - box_loss: 0.0044 - reg_l2_loss: 0.0634 - loss: 0.8442 - learning_rate: 0.0099 - gradient_norm: 1.9342 - val_det_loss: 0.9141 - val_cls_loss: 0.4919 - val_box_loss: 0.0084 - val_reg_l2_loss: 0.0634 - val_loss: 0.9775 Epoch 5/50 16/16 [==============================] - 46s 3s/step - det_loss: 0.6327 - cls_loss: 0.4590 - box_loss: 0.0035 - reg_l2_loss: 0.0634 - loss: 0.6961 - learning_rate: 0.0098 - gradient_norm: 2.4829 - val_det_loss: 0.6877 - val_cls_loss: 0.4158 - val_box_loss: 0.0054 - val_reg_l2_loss: 0.0634 - val_loss: 0.7511 Epoch 6/50 16/16 [==============================] - 40s 2s/step - det_loss: 0.5148 - cls_loss: 0.3654 - box_loss: 0.0030 - reg_l2_loss: 0.0634 - loss: 0.5782 - learning_rate: 0.0097 - gradient_norm: 2.0064 - val_det_loss: 0.6624 - val_cls_loss: 0.3615 - val_box_loss: 0.0060 - val_reg_l2_loss: 0.0634 - val_loss: 0.7258 Epoch 7/50 16/16 [==============================] - 39s 2s/step - det_loss: 0.4151 - cls_loss: 0.2857 - box_loss: 0.0026 - reg_l2_loss: 0.0634 - loss: 0.4786 - learning_rate: 0.0096 - gradient_norm: 1.8357 - val_det_loss: 0.5232 - val_cls_loss: 0.3218 - val_box_loss: 0.0040 - val_reg_l2_loss: 0.0634 - val_loss: 0.5866 Epoch 8/50 16/16 [==============================] - 40s 3s/step - det_loss: 0.4025 - cls_loss: 0.2825 - box_loss: 0.0024 - reg_l2_loss: 0.0635 - loss: 0.4659 - learning_rate: 0.0094 - gradient_norm: 2.3049 - val_det_loss: 0.6151 - val_cls_loss: 0.3453 - val_box_loss: 0.0054 - val_reg_l2_loss: 0.0635 - val_loss: 0.6786 Epoch 9/50 16/16 [==============================] - 40s 3s/step - det_loss: 0.3461 - cls_loss: 0.2444 - box_loss: 0.0020 - reg_l2_loss: 0.0635 - loss: 0.4096 - learning_rate: 0.0093 - gradient_norm: 2.0001 - val_det_loss: 0.4147 - val_cls_loss: 0.2451 - val_box_loss: 0.0034 - val_reg_l2_loss: 0.0635 - val_loss: 0.4782 Epoch 10/50 16/16 [==============================] - 41s 3s/step - det_loss: 0.3328 - cls_loss: 0.2338 - box_loss: 0.0020 - reg_l2_loss: 0.0635 - loss: 0.3963 - learning_rate: 0.0091 - gradient_norm: 1.9760 - val_det_loss: 0.3180 - val_cls_loss: 0.2151 - val_box_loss: 0.0021 - val_reg_l2_loss: 0.0635 - val_loss: 0.3815
実際の学習過程が出力されていて、学習が正常に行われているかを確認することができます。
val_lossの数値が徐々に小さくなっていることが確認できれば大方うまくいってると思って大丈夫です。
うまく学習できていない場合、val_loss部分が初めから「0.000」で変化しない場合が多いと思います。
その場合は、アノテーションCSV部分で誤りがあることが大半だと思います。
アノテーションCSVのx/yの数字を見直したり、画像パスを見直したりしましょう。
model.evaluate(test_data)
1/1 [==============================] - 6s 6s/step
{'AP': 0.91557753,
'AP50': 1.0,
'AP75': 1.0,
'AP_/Scissors': 0.9158746,
'AP_/label': -1.0,
'AP_/paper': 0.93646866,
'AP_/rock': 0.89438945,
'APl': 0.91557753,
'APm': -1.0,
'APs': -1.0,
'ARl': 0.9261905,
'ARm': -1.0,
'ARmax1': 0.91952384,
'ARmax10': 0.9261905,
'ARmax100': 0.9261905,
'ARs': -1.0}モデルを評価して確認
model.export(export_dir=SAVE_PATH) model.evaluate_tflite(str(SAVE_PATH) + '/model.tflite', test_data)
18/18 [==============================] - 38s 2s/step
{'AP': 0.9018482,
'AP50': 1.0,
'AP75': 1.0,
'AP_/Scissors': 0.87204623,
'AP_/label': -1.0,
'AP_/paper': 0.93646866,
'AP_/rock': 0.8970297,
'APl': 0.9018482,
'APm': -1.0,
'APs': -1.0,
'ARl': 0.91190475,
'ARm': -1.0,
'ARmax1': 0.91190475,
'ARmax10': 0.91190475,
'ARmax100': 0.91190475,
'ARs': -1.0}学習モデルをgoogle driveに保存して、テストデータを使ってtfliteモデルを最終評価します。
-
-
-
-
- 関連記事-----
-
-
-
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
Raspberry Pi4 画像認識 ~⑤独自画像学習 アノテーションデータ変更~
前回はじゃんけんの手をアノテーションしました。
今回はそれを「Tensorflow model maker」というTensorflowが作成したツールに読み込める様、変更していきます。
コードはgoogle colaboratoryで共有していますので、適宜変更して頂けると使用できます。
コードの解説を簡単に行っていきます。
1. 下準備
#必要なライブラリをインポートする import pandas as pd import numpy as np import cv2
pandasはアノテーションcsvを確認、編集するため
numpyはアノテーションcsvの数値を変更・計算するため
cv2(opencv)は画像を表示、確認するため
に使用します。
# MIN_DIR,CSVのパスは適宜変更してください MAIN_DIR = "/content/drive/MyDrive/ML/Tensorflow/dataset_janken/" CSV = MAIN_DIR + "janken_dataset-export.csv"
アノテーションcsvの格納されているディレクトリを「MAIN_DIR」に指定
csvのパスを「CSV」で指定
# pandasでcsvを確認 df = pd.read_csv(CSV) df image xmin ymin xmax ymax label 0 choki_01.jpg 68.710074 15.982533 236.703522 221.397380 Scissors 1 IMG_0728.JPG 62.420147 35.371179 245.090090 195.458515 rock 2 IMG_0729.JPG 65.565111 21.222707 256.097461 193.362445 rock 3 IMG_0731.JPG 73.951679 24.104803 217.047502 205.938865 rock 4 IMG_0730.JPG 84.434889 26.724891 239.848485 211.441048 rock ... ... ... ... ... ... ... 162 IMG_0890.JPG 102.780508 51.615721 237.489762 192.576419 rock 163 IMG_0892.JPG 48.267813 26.200873 208.136773 189.694323 rock 164 IMG_0891.JPG 91.773137 41.659389 235.917281 195.458515 rock 165 IMG_0893.JPG 89.152334 27.510917 248.759214 200.174672 rock 166 IMG_0894.JPG 47.481572 24.890830 213.116298 195.982533 rock
pandasの説明はここでは省きます。csvの中身が確認できます。
2. csvファイルの変更
2-1. 画像名を画像パスに変更する
# imageの値をパスに変更する for idx, col in enumerate(df.image): df.image[idx] = MAIN_DIR + col df.head() image xmin ymin xmax ymax label 0 /content/drive/MyDrive/ML/Tensorflow/dataset_j... 68.710074 15.982533 236.703522 221.397380 Scissors 1 /content/drive/MyDrive/ML/Tensorflow/dataset_j... 62.420147 35.371179 245.090090 195.458515 rock 2 /content/drive/MyDrive/ML/Tensorflow/dataset_j... 65.565111 21.222707 256.097461 193.362445 rock 3 /content/drive/MyDrive/ML/Tensorflow/dataset_j... 73.951679 24.104803 217.047502 205.938865 rock 4 /content/drive/MyDrive/ML/Tensorflow/dataset_j... 84.434889 26.724891 239.848485 211.441048 rock
2-2. xmin/ymin/xmax/ymaxの値を正規化する
img = cv2.imread(df.image[0])
y, x, _ = img.shape
for idx, col in enumerate(df.xmin): df.xmin[idx] = col / x for idx, col in enumerate(df.ymin): df.ymin[idx] = col / y for idx, col in enumerate(df.xmax): df.xmax[idx] = col / x for idx, col in enumerate(df.ymax): df.ymax[idx] = col / y df.head() image xmin ymin xmax ymax label 0 /content/drive/MyDrive/ML/Tensorflow/dataset_j... 0.214719 0.066594 0.739699 0.922489 Scissors 1 /content/drive/MyDrive/ML/Tensorflow/dataset_j... 0.195063 0.147380 0.765907 0.814410 rock 2 /content/drive/MyDrive/ML/Tensorflow/dataset_j... 0.204891 0.088428 0.800305 0.805677 rock 3 /content/drive/MyDrive/ML/Tensorflow/dataset_j... 0.231099 0.100437 0.678273 0.858079 rock 4 /content/drive/MyDrive/ML/Tensorflow/dataset_j... 0.263859 0.111354 0.749527 0.881004 rock
今回は、すべての画像が同じ大きさなので、1枚の画像を参照しています。
1枚の画像の縦・横のpx数を取得し、xmin/xmaxをxで、ymin/ymaxをyで割ることで、0.0-1.0の間の数値に正規化します。
2-3. 新たな列を追加して、列を並べ替える
df["type"] = "" df["dummy_1"] = "" df["dummy_2"] = "" df["dummy_3"] = "" df["dummy_4"] = "" df = df.reindex(columns=["type","image","label","xmin","ymin","dummy_1","dummy_2","xmax","ymax","dummy_3","dummy_4"]) df.head() type image label xmin ymin dummy_1 dummy_2 xmax ymax dummy_3 dummy_4 0 /content/drive/MyDrive/ML/Tensorflow/dataset_j... Scissors 0.214719 0.066594 0.739699 0.922489 1 /content/drive/MyDrive/ML/Tensorflow/dataset_j... rock 0.195063 0.147380 0.765907 0.814410 2 /content/drive/MyDrive/ML/Tensorflow/dataset_j... rock 0.204891 0.088428 0.800305 0.805677 3 /content/drive/MyDrive/ML/Tensorflow/dataset_j... rock 0.231099 0.100437 0.678273 0.858079 4 /content/drive/MyDrive/ML/Tensorflow/dataset_j... rock 0.263859 0.111354 0.749527 0.881004
tensorflow model makerの物体検出ツールではcsvの読み込み形式が決まっており、ダミーの列を追加し、既定の場所に数値が入っていなければうまく動作してくれません。
2-4. 列typeにtrain/validation/testを割り振る
tmp = df[df.label == "rock"].index.tolist() train_index = tmp[0:int(len(tmp)*0.8)] validation_index = tmp[int(len(tmp)*0.8):int(len(tmp)*0.9)] test_index = tmp[int(len(tmp)*0.9):len(tmp)] for idx in train_index: df["type"][idx] = "TRAIN" for idx in validation_index: df["type"][idx] = "VALIDATION" for idx in test_index: df["type"][idx] = "TEST"
tmp = df[df.label == "Scissors"].index.tolist() train_index = tmp[0:int(len(tmp)*0.8)] validation_index = tmp[int(len(tmp)*0.8):int(len(tmp)*0.9)] test_index = tmp[int(len(tmp)*0.9):len(tmp)] for idx in train_index: df["type"][idx] = "TRAIN" for idx in validation_index: df["type"][idx] = "VALIDATION" for idx in test_index: df["type"][idx] = "TEST"
tmp = df[df.label == "paper"].index.tolist() train_index = tmp[0:int(len(tmp)*0.8)] validation_index = tmp[int(len(tmp)*0.8):int(len(tmp)*0.9)] test_index = tmp[int(len(tmp)*0.9):] for idx in train_index: df["type"][idx] = "TRAIN" for idx in validation_index: df["type"][idx] = "VALIDATION" for idx in test_index: df["type"][idx] = "TEST"
次に、type列にtrain/validation/testという割り振りをします。
機械学習では、データを分割して、「学習用/検証用/試験用」として学習の時に、学習用画像を学習してモデルを作り、検証用画像でその正確性を評価します。
最終的に試験用画像で、最終的な学習モデルを評価します。
2-5. 保存
df.to_csv(MAIN_DIR + "dataset.csv", index=False)
以上までで行った処理したデータをcsvとして保存して終了です。
-
-
-
-
- 関連記事-----
-
-
-
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
Raspberry Pi4 画像認識 ~④独自画像学習 アノテーション~
0.初めに
「Raspberry Pi4 リモートで初期設定 Raspberry Pi OS/OS Lite」、「Raspberry Pi4でTensorflow Lite 環境を構築してみる」、「Raspberry Pi 4で物体検出してみる」の3記事にわたって、Raspberry Pi4のセットアップとtensorflow・tensorflow Liteの動作環境を準備し、動作の確認を行ってきました。
ただし、使用した学習モデルは一般で気に出回っているモノを検出するモデルで、「自分が検出したいモノ」を検出できるようになっているわけではありません。
「自分が検出したいモノ」の画像、もしくは動画から検出したいモノを四角で囲う作業(アノテーション)を行ってまいりますので、画像を用意してください。
今回は、karaage0703さんのjanken_datasetを用いて検出してみます。
1.datasetをダウンロード
上記のデータセットを自分のPCにダウンロードします。
code部分からDownload ZIPでダウンロードし、解凍します。

2.Vottのインストール
アノテーション作業を行うためのアプリは様々ありますが、ここでは「Vott」というアプリを使用していきます。
まず、こちらからVottをインストールします。
github.com
3.アノテーション作業
インストールが完了し、アプリを起動するとこのようになります。
まず、新規プロジェクトを作成します。
次に、表示名、ソース接続、ターゲット接続を記入していきます。
表示名はお好みでつけてください。ここではtflite_testとしました。
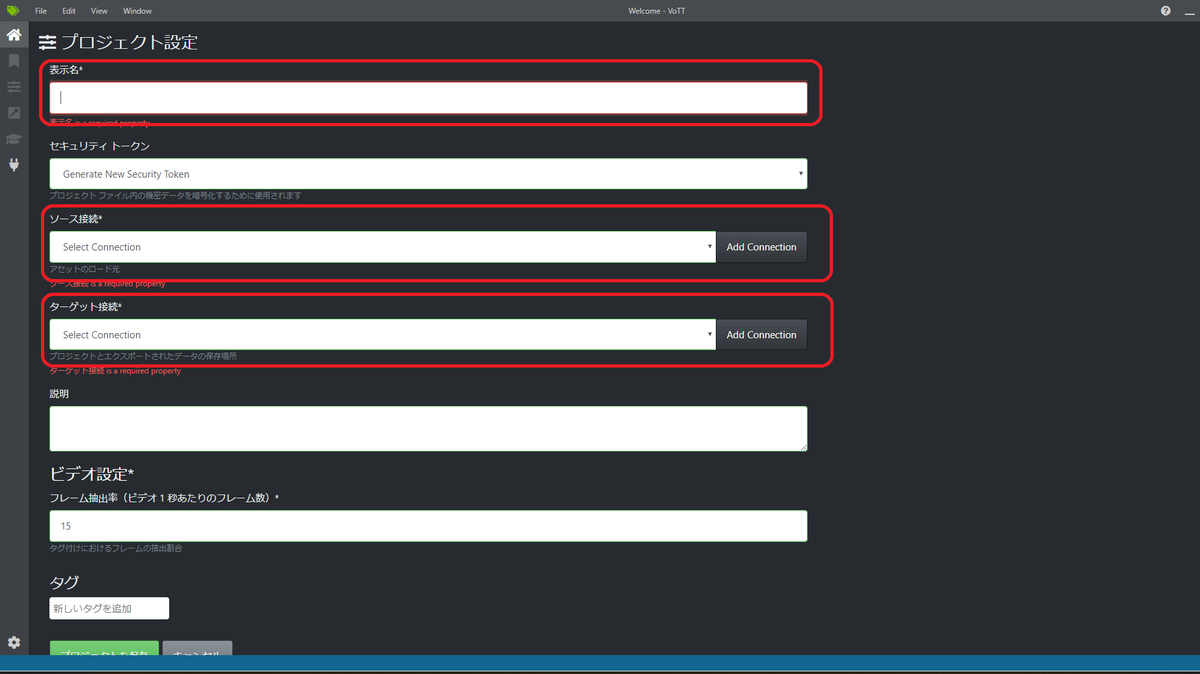
ソース接続、ターゲット接続の設定はそれぞれ右側にある「Add Connection」から設定します。
「Add Connection」を押すと次のような画面になります。
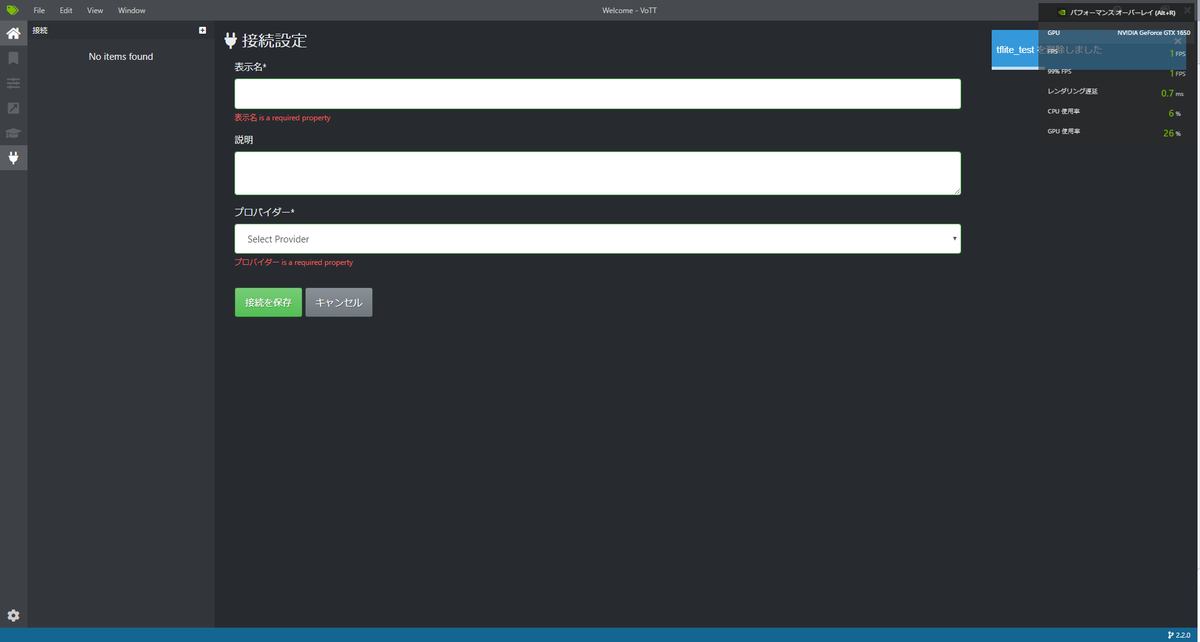
プロバイダーというところをクリックするとどこから画像を引っ張ってくるかを選択することができます。
「Azure Blob strage」や「bing 画像検索」などがありますが、今回は「ローカルファイルシステム」でPCに入っている画像を使用するので、その画像が入っているフォルダを指定します。
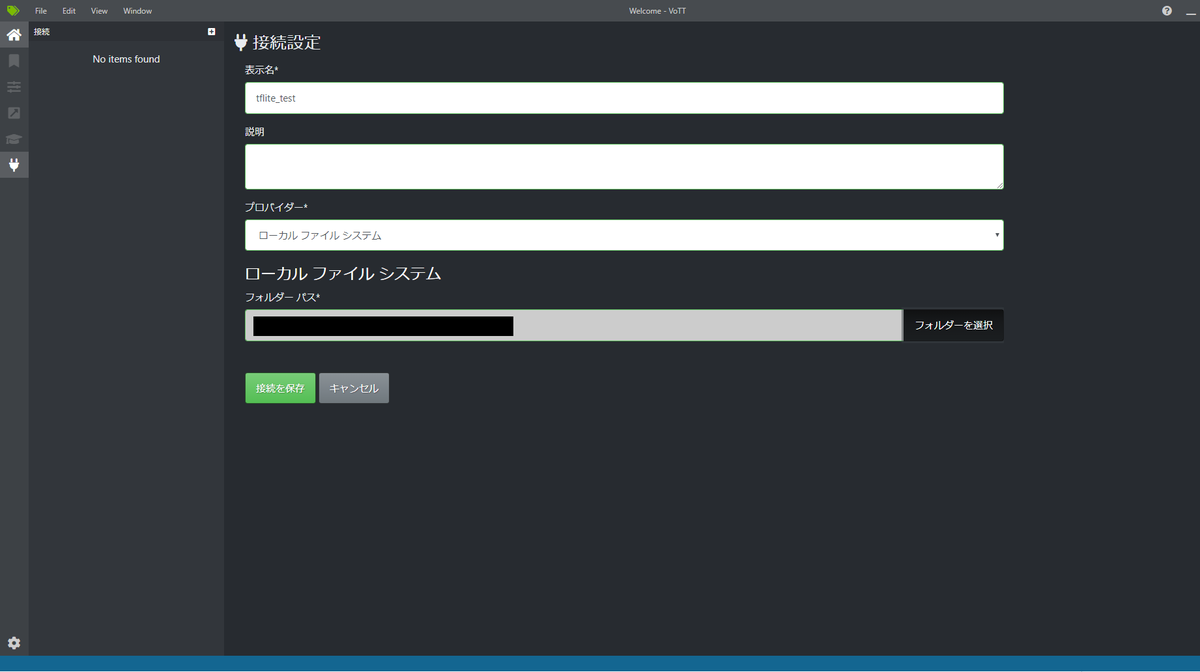
そして、「ソース接続」「ターゲット接続」のプルダウンから、今作成したパスを選択すれば完了なので、プロジェクトを保存をおします。
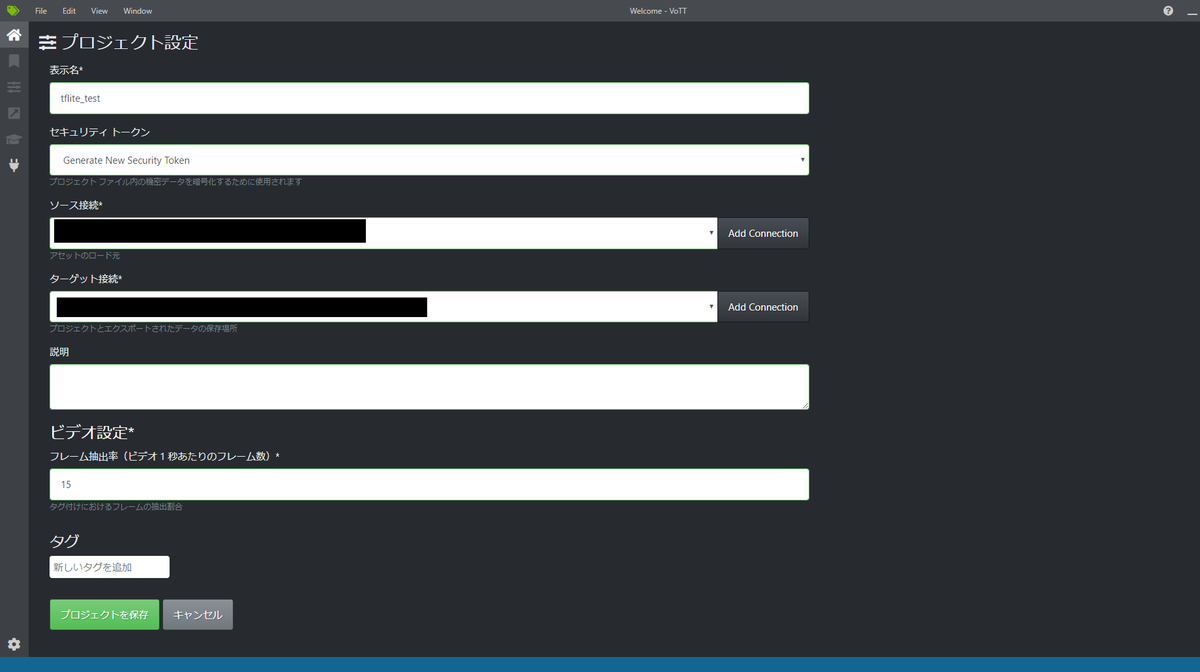
するとフォルダー内にある画像すべてが表示されます。
まず、「手」をタグ付けするために、右上「TAG」の横にあるプラスマークをおしてタグの名前を必要なだけ用意します。
その後、上部にある四角を押すことで、囲うことができます。
それぞれ、検出する「手」に対応したタグをつけることで、アノテーションができます。


4.アノテーションしたデータのエクスポート
この後行うモデルの学習で必要なデータ形式に変更する必要があります。
今回は、model makerで行うため、excelで出力するように設定をします。
また、「アセットの状態」は必ずタグ付きアセットのみにしてください。
エクスポート設定が終了したら、赤枠部分のエクスポートを実行すると出力されます。

今回は以上で終わります。
お疲れさまでした。
-
-
-
-
- 関連記事-----
-
-
-
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
Raspberry Pi4 画像認識 ~③物体検出 動作確認~
初めに
使用するのは、「Raspberry Pi4でTensorflow Lite 環境を構築してみる」<-「Raspberry Pi4 リモートで初期設定 Raspberry Pi OS/OS Lite」で設定したRaspberry Pi4を使用します。
melostark.hatenablog.com
melostark.hatenablog.com
「Raspberry Pi4でTensorflow Lite環境を構築してみる」で環境構築はできたので、Tensorflow公式のexampleで動作確認をしてみます。
1. Tensorflow 公式ページを見てみる
「Tensroflow Liteサンプル | 機械学習モバイルアプリ」というページを見てみると、
- 画像分類
- オブジェクト検出
- 姿勢推定
- 音声認識
- ジェスチャー認識
- セグメンテーション
- テキスト分類
- デバイス上のおすすめ
- 自然言語で質問に回答
- 数字分類器
- 画風変換
- スマートリプライ
- 超解像
- 音声分類
- Reinforcement learning(強化学習)
- Optical character recognition(光学的文字認識)
いろいろあって面白そうですが、とりあえずオブジェクト検出をやってみましょ。
オリンピックのピクトグラムで話題になった「Tokyo2020-Pictogram-using-MediaPipe」はおそらく「姿勢推定」を使用したアプリのようですね!
アイディアとプロトタイプ実装までのスピードが速くて、陰ながら尊敬しておりますし、ほかにも面白いアプリを作成されているので、ご覧になってみてください。
はなしが脱線してしまいましたが、オブジェクト検出に戻りましょう。
先ほどのページの「オブジェクト検出」の「Raspberry Piで試してみる」からgithubに移行するので、READMEの通りに実行していきます。
github.com
2. githubからリポジトリをクローンして動かしてみる
まずは、READMEの通りに進めていきます。
2-1. Set up your hardware
こちらは、以前の記事の方で行っているので、特に何もしなくても問題ありません。
2-2. Download the example files
ここも、以前の記事で行った設定をもとに行っていきます。
設定を行っていない場合、READMEの通りに行えばテストできると思いますが、こちらでは検証しておりません。
pi@raspberrypi:~ $ cd workspace/tflite pi@raspberrypi:~/workspace/tflite $ source venv-tflite-v1/bin/activate (venv-tflite-v1) pi@raspberrypi:~/workspace/tflite $ (venv-tflite-v1) pi@raspberrypi:~/workspace/tflite $ git clone https://github.com/tensorflow/examples --depth 1 (venv-tflite-v1) pi@raspberrypi:~/workspace/tflite $ cd examples/lite/examples/object_detection/raspberry_pi
2-3. Run the example
あとは、事前に用意されているプログラムを実行するだけでPicameraで見ている映像のなかでオブジェクト検出してくれます。
(venv-tflite-v1) pi@raspberrypi:~/workspace/tflite $ python3 detect.py \ --model efficientdet_lite0.tflite
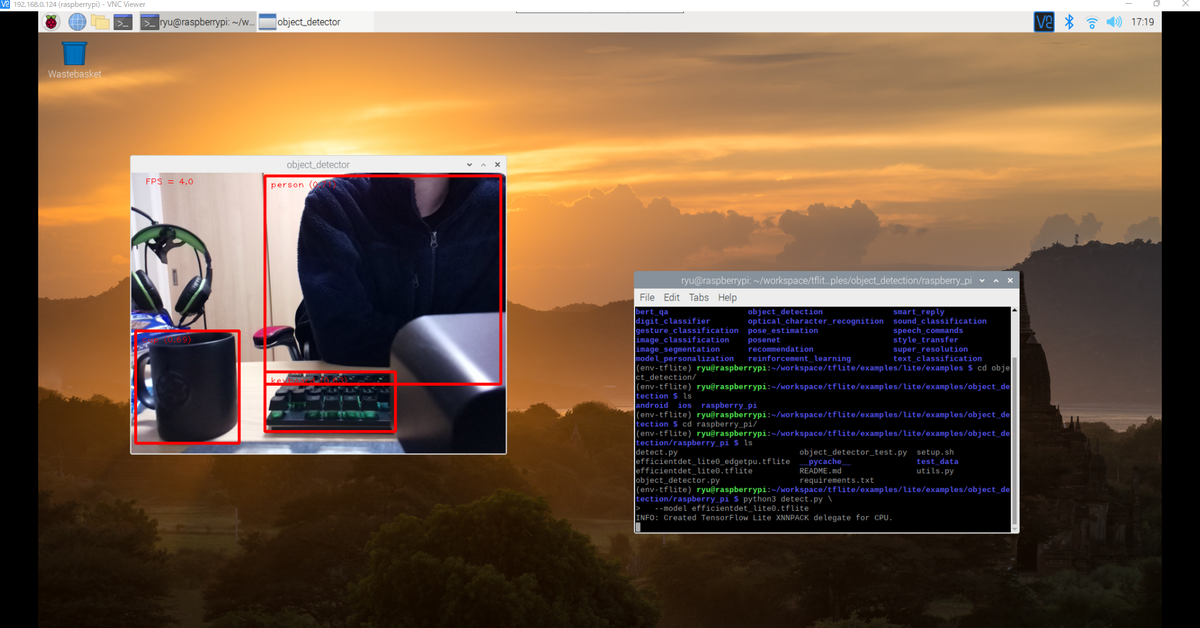
なんだか検出してくれていそうですね!
カップは全身が写っていますが、人やキーボードは半分程度しか映っていないにもかかわらず、検出してくれいています。
これでRaspbrry Piで物体検出ができることを確認することができました。
では、つぎはなんだかわからない学習済みのモデルではなく、自分で分類したいものを学習したモデルを作成してみることにします!
今回はここで終了します。
お疲れさまでした。
-
-
-
-
- 関連記事-----
-
-
-
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
Raspberry Pi4 画像認識 ~②Tensorflow Lite 環境構築~
2022/6/4 更新
2021/10/18 更新
初めに
使用するのは「Raspberry Pi4 リモートで初期設定 Raspberry Pi OS/OS Lite」で構築したデスクトップ環境のラズパイ4で行います。
melostark.hatenablog.com
1. Tensorflow Liteの環境準備 -作業用フォルダの作成-
これからこのラズパイで様々な実験を行っていくことを考慮して、作業用フォルダと仮想環境を準備します。
仮想環境を作る理由としては、pythonのパッケージバージョンの違いで様々なエラーが出ることがあり、
独立した環境の方がそういったエラーが出なくて済むためです。
pi@raspberrypi:~ $ mkdir workspace pi@raspberrypi:~ $ cd workspace pi@raspberrypi:~/workspace $ mkdir tflite pi@raspberrypi:~/workspace $ cd tflite pi@raspberrypi:~/workspace/tflite $
これからプログラムを書くなどの作業するのは基本「~/workspace」というディレクトリで行い、
Tensorflow Liteを動かすのは「~/workspace/tflite」で行います。
では、pythonの仮想環境を作ります。
pi@raspberrypi:~/workspace/tflite $ python3 -V Python 3.7.3 pi@raspberrypi:~/workspace/tflite $ python3 -m venv venv-tflite-v1 pi@raspberrypi:~/workspace/tflite $ source venv-tflite-v1/bin/activate (venv-tflite-v1) pi@raspberrypi:~/workspace/tflite $
python 3.3から導入されたvenvで仮想環境を作りました。
pythonに標準で入っているパッケージのため、python事態のバージョン管理はできません。
2. Tensorflowをインストールする
PINTO0309さんという方が用意してくださっているTensorflow-binというリポジトリのお力をお借りしてインストールしたいと思います。
github.com
基本、上記READMEの通りに進めれば何も問題がありません。
この後行う物体検出のモデル作成に使用するTensorflowのバージョンと合わせておくのが良いでしょう。
また別途更新する予定ですが、tflite形式の物体検出モデルを作成するのであれば、「TFlite Model Maker」が最も直接的で煩わしくないと思います。
www.tensorflow.org
※2022/6/4 テスト段階 Tensorflow == 2.8.0
※2021/10/18テスト段階 Tensorflow==2.5.0
では、Tensorflow 2.8.0をTensorflow-binリポジトリからインストールします。
必要に応じて「previous_versions」から
sudo apt-get install -y libhdf5-dev libc-ares-dev libeigen3-dev gcc gfortran \
libgfortran5 libatlas3-base libatlas-base-dev \
libopenblas-dev libopenblas-base libblas-dev \
liblapack-dev cython3 libatlas-base-dev openmpi-bin \
libopenmpi-dev python3-dev python-is-python3
sudo pip3 install pip --upgrade
sudo pip3 install keras_applications==1.0.8 --no-deps
sudo pip3 install keras_preprocessing==1.1.2 --no-deps
sudo pip3 install numpy==1.22.1
sudo pip3 install h5py==3.6.0
sudo pip3 install pybind11==2.9.2
pip3 install -U --user six wheel mock
./previous_version/download_tensorflow-2.8.0-cp39-none-linux_aarch64_numpy1221.sh
sudo -H pip3 install tensorflow-2.8.0-cp39-none-linux_aarch64.whl念のためpython3でインポートできるか確認
$ python3 >>> import tensorflow as tf >>> print(tf.__version__) 2.8.0 >>>exit() $ $ cd ../ $ rm -rf Tensorflow-bin $
以上で、Tensorflow==2.8.0のインストールは完了です。
3. Tensorflow Liteを使うためのライブラリインストール
colabで用いたものをそのまま使用したらうまくいきました。
pip3 install tflite-support
念のため、python3でインポートできるかを確認
$ python3 >>> from tflite_runtime.interpreter import Interpreter >>>
エラーが出なければ完了です。
これで、TensorflowLiteの環境設定は完了しました。
あと、画像解析ライブラリでよく使われる「Pillow」と「OpenCV」をインストールしておきます。
$ pip3 install Pillow==5.4.1 $ pip3 install opencv-python
以上で、必要なものはそろいました。
お疲れさまでした。
-
-
-
-
- 関連記事-----
-
-
-
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
Raspberry Pi4 画像認識 ~①リモートで初期設定 Raspberry Pi OS/OS Lite~
0. 初めに
Raspberry Pi(以下ラズパイ)で物体検出をテストするためにセットアップを行っていきます。
物体検出のテストを行うなら基本は「Raspberry Pi OS」で動作させると思いますが、「Raspberry Pi OS Lite」でプログラムを動かしてリモート接続したPCから遠隔で確認するなどの使い方もあります。
両方のOSに対応できる様にリモート接続して行う初期設定を備忘録として記録しておきます。
1. Raspberry pi4のセットアップ - ラズパイ一式とOSの準備 -
1-1. ラズパイ4とPi cameraの購入
何はともあれ、まずはラズパイとカメラを用意します。
前提として、OSを書き込む等に使用するデスクトップPC/ノートPC を持っているとして話を進めます。
今回はwindowsでセットアップを行います。
まずラズパイ4本体、自分は下記を購入しました。
技適マーク付/MicroSDHCカード128GB NOOBSプリインストール/簡単に取り付けるケース/5.1V/3A Type-C スイッチ付電源/2つのMicroHDMI-to-HDMIケーブルライン/3つヒートシンクと2つの透明静音冷却ファン/カードリーダ /GPIOリファレンスカード/日本語取扱説明書/2年保証付")
ラズパイ4は性能が大きく向上したため、普段使いなどでもヒートシンクなどを付けた方がいいようです。
無論、CPUで機械学習モデルを動かすなんてことをするならなおさら必要です。
microSDカードやスイッチ付きの電源コードなどがすべてまとまっているキットを購入するのが一番楽でお金もかからないように思います。
次にラズパイに接続するカメラです。

Pi cameraだけでなく、USBカメラで利用することができますが、ここでは扱いません。
以上を購入すればとりあえず必要なものはそろいました。

1-2. OSのインストール
ラズパイを動かすためのOSをmicroSDカードに入れていきます。
ご自分のPCとSDカードリーダー、上で購入したセットに同封されているmicroSDカードとSDカードリーダーを用意してください。
1. まず、「Raspberry Pi Imager」をご自分のPCにインストールします。
www.raspberrypi.com
2. ダウンロードしたimagerを起動すると下記の様な画像が表示されます。
「CHOOSE OS」をクリックします。

3. まずmicroSDカードをフォーマットするために、「ERASE」を選択します。
4. 「CHOOSE STORAGE」からカードリーダーで読み込んだSDカードを選択します。

5. 「WRITE」をクリックすれば、SDカードがフォーマットされます。

6. 今度は、「CHOOSE OS」から、OSを選択します。今回は「Raspberry Pi OS(32-bit)」を入れます。

7. 再度「WRITE」をクリックすればSDカードにOSイメージが書き込まれます。

ここから、入れたOS毎に若干設定が異なるので「Raspbery Pi OS」と「Raspberry Pi OS Lite」で設定の方法が異なるので、共通の設定方法を書いていきます。
2. ラズパイのリモート設定 - 共通設定方法 -
Desktop OSであれば、モニターなどをつないでGUIで設定ができますが、デスクトップ環境でないOS Liteの場合、リモートで設定しなければなりません。
Desktop OSの場合でもLite OSの場合でもCUI環境から設定を行うことができるので、共通してCUIで設定を行います。
ここからSDカードにリモートでセットアップするための設定を2つ行っていきます。
2-1. sshファイル作成
まず、「Raspberry Pi Imager」で書き込んだ後、SDカードが認識されていないので、SDカードをさしなおします。
エクスプローラーからSDカードの「boot」に「ssh」というファイルを作成します。
bootフォルダ上で右クリックで 新規作成->テキスト ドキュメント を選び、「ssh」と記入して「.txt」部分を削除すれば完了です。
2-2. Wifi接続するための設定ファイル作成
2-1. sshファイル作成と同様に bootフォルダ上で右クリックで 新規作成->テキスト ドキュメント を選び、「wpa_supplicant.conf」と記入して「.txt」部分を削除します。
今度は、「wpa_supplicant.conf」をメモ帳などのエディタで開いて下記内容を書き込みます。
ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdev
update_config=1
country=JP
network={
ssid="<SSID名>" # 接続したいwifiの名称
psk="<パスワード>" # 上で選択したwifiのパスワード
}
3. ラズパイにssh接続
2で行った設定でラズパイはWifiに接続されているはずなので、Teratermを使ってラズパイにssh接続します。
teratermをインストールしましょう。
forest.watch.impress.co.jp
まず、windowsPCからコマンドプロンプトを使ってラズパイがWifiに接続されているかを確認してみます。
ping -4 raspberrypi.local
これで応答が返ってこない場合、ラズパイがWifiに接続できていないことが考えられます。
WifiのSSIDやパスワードが間違っているのが一番考えられるため、もう一度SDカードを設定しなおしてください。
Teratermを起動してラズパイに接続してみます
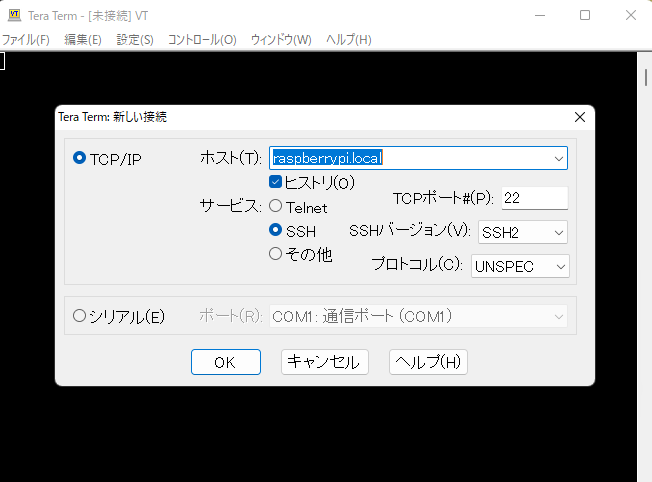
ホスト(T)に「raspberrypi.local」と入力してOKを押します。
セキュリティ警告が出てきますがそのまま「続行」を押して大丈夫です。
ユーザー名は「pi」
パスフレーズは「raspberry」でOKを押します。
するとこのような画面に移ります。
これで、接続が完了しました。
4. ラズパイの各種設定
4-2. Wifiの接続パス暗号化(任意)
やっておいた方が安心です。
sudo sh -c 'wpa_passphrase SSID PASSPHRASE >> /etc/wpa_supplicant/wpa_supplicant.conf'
上記を行った後、/etc/wpa_supplicant/wpa_supplicant.conf には新たにWifi設定が書かれるので、1-3で記入したWifi設定とコメントアウトされているpsk部分を削除します。
sudo nano /etc/wpa_supplicant/wpa_supplicant.conf
4-3. IPアドレスの固定
ラズパイが接続するWifiのIPアドレスを固定します。
この後VNC接続でラズパイのデスクトップ画面をPCから操作するためにも必要がありますので行います。
sudo nano /etc/dhcpcd.conf
これで出てきたファイル内の一番下に下記を追加します。
# *の部分はWifiのIPアドレス設定状況によって異なりますので適宜変更してください。 interface wlan0 static ip_address=192.168.*.**/24 static routers=192.168.*.* static domain_name_servers=192.168.*.*
4-4. Localisation変更
sudo raspi-config
上記を実行すると下記の様な画面が出てきます。
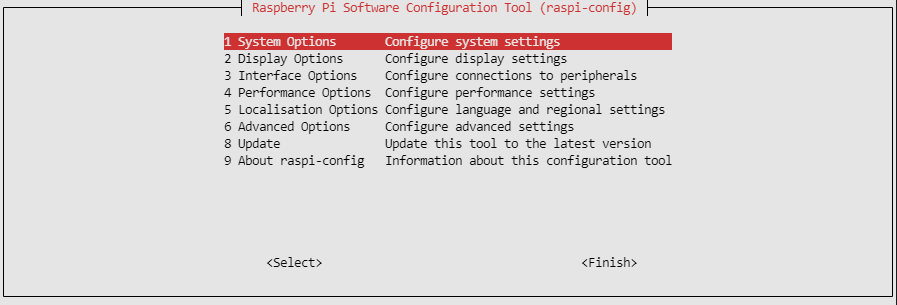
1. [5 Localisation Options] -> [L1 Locale]
「en_us.UTF-8」「ja_jp.UTF8」「ja_jp.EUC-JP」を追加して、default system localを「ja_jp.UTF8」に変更します。
2. [5 Localisation Options] -> [L2 Timezone]
「Asia」→「Tokyo」を選択します。
3. [3 Interface Options] -> [P1 Camera]
Pi Camera I/Fを使いますのでEnabelにして下さい。
4. [3 Interface Options] -> [P3 VNC]
Raspberry Pi OSの場合、モニター画面をリモートで接続しているPCから閲覧、操作できるようにします。
以上で、「Raspberry Pi OS」「Raspberry Pi OS Lite」両方で基本設定が終わりました。
5.windowsPCからラズパイにVNC接続する
基本的にCUI画面で操作を行っていきますが、ラズパイカメラの画像をラズパイ上で確認したいときなどに使用します。
Windows PC上の操作になります。
VNC接続するために「VNC Viewer」をダウンロード/インストールします。
VNC viewerを起動すると下記の様な画面が表示されるので、1-5-3で設定したIPアドレスを入力します。
「Username」欄、「Password」欄にそれぞれ「pi」、「1-5-1で変更したパスワード」を入力し、「OK」をクリックします。
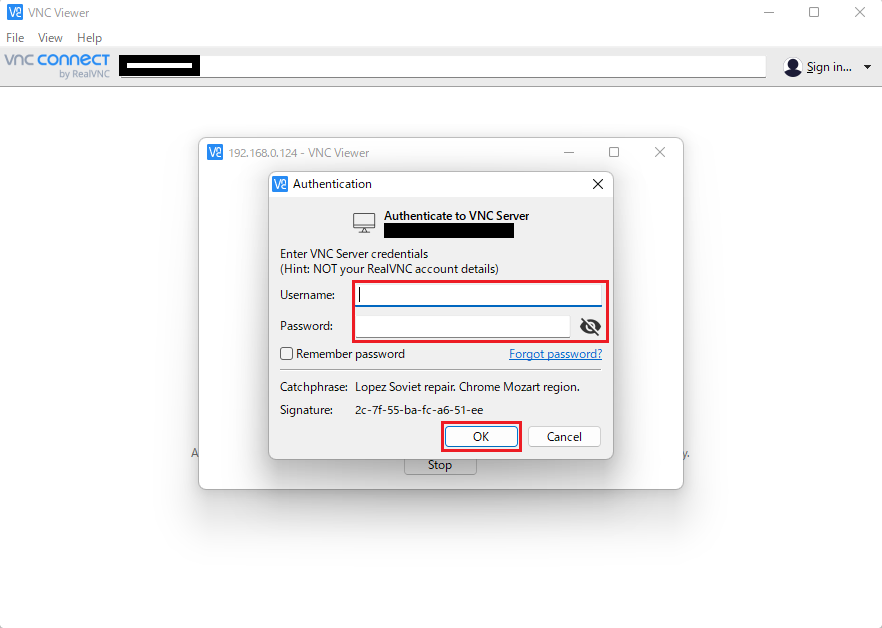
そうすると「Raspberry Pi OS」のデスクトップ画面が操作できるようになります。

以上で、ラズパイのデスクトップ画面にVNC接続できるようになりました。
以上で、ラズパイの初期設定は終了です。
お疲れさまでした。
-
-
-
-
- 関連記事-----
-
-
-
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
melostark.hatenablog.com
Pythonコーディング練習 : 4日目
Pythonコーディング練習 : 4日目
Practice Python Exercise 11 ~ 18
勉強時間 : 30分×10 = 5時間
Practice Pythonの折り返し地点まで来ましたー。
これ初めはいいと思っていたんですが、答えがちょこちょこ間違っていることがありますね。
日本語版Practice Pythonはあるのかな?
問題と答えを日本語にすると多少需要がありそうなので気が向いたらやります。
ちなみに突然練習問題17でスクレイピングの問題が出てきたけどめんどくさいので飛ばしました。
Webサイトなんて毎回更新されてデータ構造も変わるから問題としてはいわゆる悪問になってしまいますよね。
やらせるなら自分で作成したサイトを使う必要がありますよね。
では折り返し、残り半分頑張ります。
Pythonコーディング練習 : 3日目
Pythonコーディング練習 : 3日目
Practice Python Exercise 9 ~ 10
勉強時間 : 30分×3 = 1.5時間
で参考にさせていただいた
何ですが、いまいちコードテストがこのPython Practiceで上手に使えずにいます。。。
ユニットコードテストの有用性はなんとなく理解していますが、任意の値(ランダムな値)特に、数値を入力するような問題であれば使用できるが、言語の場合テスト方法がわからず、現在ユニットコードテストは使用していません。
問題で解いた関数内で乱数生成して、プログラム内でテストしてしまっています。
ただし、乱数のためにその乱数を表示して自分で確認しない限り、正解不正解がわからないのでやっぱりコードテストした方が圧倒的にいいですよね。。。
Practice Pythonが一通り終わったらコードテストを徐々に取り入れていこうと思います。
jsonファイルとかどういうものかちゃんと理解してないので、自分で使ってみるとためになりますしね。